Introduzione al Sistema Operativo Linux
Organizzazione logica dei file
- In Unix tutto si può definire un file.
- in Unix i tipi di file sono:
- file ordinari (insieme di byte);
- directory (raggruppare in modo logico i file);
- file speciali (special device file) per la rappresentazione di periferiche (device indipendent);
- il nome di un file può contenere lettere, cifre o segni speciali quali il punto “.” o il segno di sottolineato “_”; meglio evitare il meno “-“;
- i file con il nome che inizia con un punto si chiamano dot file e indicano di solito i file nascosti (hidden file);
- il S.O. Unix considera come caratteri diversi le lettere minuscole e maiuscole (case sensitive);
- il S.O. Unix per l’organizzazione logica dei file usa un sistema gerarchico di direttrici (directory) strutturato ad albero in cui i nodi sono costituiti dalle directory e le foglie file ordinari, directory vuote, file speciali;
- il punto da solo indica la directory corrente (current working directory), ovvero dove ci si trova posizionati;
- il doppio punto “..” indica la directory che sta sopra la directory corrente nell’albero delle directory;
- la directory principale è la root, o radice dell’albero, si rappresenta con il simbolo / (slash);
- ad ogni utente risulta assegnata una directory personale (home directory);
- i nomi dei file e delle directory sono rappresentati attraverso il percorso che occorre fare per arrivare al file o directory attraversando l’albero del file system (pathname):
- se il cammino parte dalla root, il nome è espresso tramite un pathname assoluto (full pathname);
- se il cammino parte dalla directory corrente si ha il pathname relativo (relative pathname);
- nella scrittura dei pathname si usa il simbolo / come separatore dei nomi di directory.
- nella scrittura dei nomi dei file e delle directory il simbolo ~ rappresenta la home directory dell’utente.
- in Unix i tipi di file sono:

Bash dei comandi
Unix ≈ Linux
Il S.O. da noi usato sarà Linux che è assai simile a Unix (i S.O. di matrice Unix vengono anche definiti Unix-like), che condivide l’impostazione e le strutture fondamentali di Unix ma, non discende da una tra le tante versioni di Unix, anzi è stato completamente riscritto dal principio, kernel compreso. Il nome Linux deriva proprio dal nome della persona che ha maggiormente contribuito alla scrittura del kernel, il finlandese Linus Torvalds: la “x” finale richiama alla mente il naturale progenitore ovvero Unix. Logo ufficiale di Linux è il pinguino disegnato da Larry Ewing.
Linux è un S.O. Open Source quindi permette agli sviluppatori una completa personalizzazione del S.O. (differenti versioni del kernel, differenti tools di installazione e configurazione, differenti gestori di finestre, ecc.); sul mercato ci sono numerose distribuzioni di Linux.
Interprete di comandi o shell del S.O.
La shell è un programma che riceve in ingresso le richieste di esecuzione di operazioni espresse usando il linguaggio di comandi. L’interprete di comandi presenta all’utente sul video una riga, sulla quale l’utente può scrivere da tastiera il comando (riga comandi), all’inizio della riga viene evidenziato un insieme di caratteri che richiamano l’attenzione dell’utente (prompt).
Una componente importante degli interpreti a riga comandi è l’analizzatore sintattico, un programma che verifica la correttezza formale (lessico e sintassi) delle richieste dell’utente, comunque una shell Unix normale svolge i compiti seguenti:
- mostra l’invito, o prompt, all’inserimento dei comandi;
- interpreta la riga di comando data dall’utente;
- esegue delle sostituzioni, in base ai caratteri jolly e alle variabili di ambiente;
- mette a disposizione alcuni comandi interni;
- mette in esecuzione i programmi;
- gestisce la ridirezione dell’input e dell’output;
- è in grado di interpretare ed eseguire dei file script.
L’interprete di comandi a cui si farà riferimento è la bash shell (Bourne again shell) che è la shell standard di Linux, il prompt di tale shell contiene fra i suoi caratteri il simbolo $.
Si può ottenere informazioni sui comandi utilizzabili attraverso il manuale in linea del S.O. attivato con il comando man. Sintassi di man è:
man nomecomando
Il comando man con l’opzione –k fornisce l’elenco dei documenti del manuale che contengono una parola chiave (keyword) specificata, esempio:
man -k print
visualizza l’elenco delle pagine del manuale in linea che contengono la parola print.
Altri modi per ottenere informazioni sono:
- comando seguito da opzione -help (nomecomando –help) si ottengono ;
- tramite info si accede al manuale completo in linea, nel punto dove ci sono le informazioni che riguardano il comando richiesto (info nomecomando);
- comando help che visualizza un elenco rapido dei comandi con una breve descrizione
- un breve indice di spiegazioni sui comandi è disponibile utilizzando il comando whatis;
- apropos cerca informazioni su un comando o argomento
- o.

Comando man
Struttura generale di un comando Linux:
PAROLA CHIAVE -OPZIONI ARGOMENTI NOME FILE
Le parole chiave dei comandi sono scritte in minuscolo.
Esempi di comandi:
- senza argomenti, opzioni e file
- pwd (visualizza il nome della directory corrente);
- cal (visualizza il calendario del mese corrente);
- con argomento
- banner Linux (scrive Linux in caratteri grandi, 132 caratteri per riga);
- cal 2003 (visualizza il calendario dell’anno 2003);
- con argomento e opzione
- banner -w50 Linux (scrive Linux con 50 caratteri per ogni riga);
- con opzione e file
- ls -l /home (visualizza la lista dei file della directory /home in formato lungo)
I comandi della shell possono essere eseguiti in successione con una sola riga di comando separandoli con il punto e virgola ; esempio: pwd; date
I comandi vengono eseguiti in foreground, cioè la shell cede il controllo al processo di esecuzione del comando e lo riprende al termine del comando. Linux permette anche l’esecuzione di un comando in background indicando al termine della riga di comandi il carattere &: la shell apre un processo che viene eseguito in parallelo alla shell stessa, che prosegue la propria esecuzione senza attendere il termine di quella del comando. Esempio:
gcc prova.c &
Alcune combinazioni speciali di tasti vi consentono di fare cose più facilmente e più rapidamente
con la shell GNU, Bash. Qui sotto c’è una lista delle funzioni più utilizzate: siete fortemente consigliati ad abituarvi
al loro uso in modo da ottenere il massimo di esperienza Linux sin dal principio.
Tasto o combinazione di tasti Funzione
Ctrl+A Muove il cursore all’inizio della linea di comando.
Ctrl+C Termina un programma attivo e ritorna al prompt.
Ctrl+D Disconnessione dalla corrente sessione di shell: corrisponde alla scrittura di exit o logout.
Ctrl+E Sposta il cursore in fondo alla linea di comando.
Ctrl+H Genera un carattere di backspace [cancellazione all’indietro].
Ctrl+L Pulisce il terminale.
Ctrl+R Ricerca nella cronologia [history] dei comandi.
Ctrl+Z Sospende un programma.
FrecciaSinistra e Sposta il cursore di una posizione a sinistra o a destra sulla FrecciaDestra linea di comando in modo che potete inserire caratteri in altri posti oltre a quelli d’inizio e fine.
FrecciaSu e Scorre la cronologia [history] dei comandi. Andate alla linea FrecciaGiù che volete ripetere, modificate i dettagli se necessario e premete Invio per risparmiare tempo.
Maiuscolo+PaginaSu e Scorre il buffer di terminale (per vedere il testo che ha
Maiuscolo+PaginaGiù “spostato” lo schermo).
Tab Completamento di comandi o nomi di file: quando sono possibili più scelte, il sistema ve lo segnalerà con un segnale sonoro o visivo, altrimenti, se le scelte sono troppe, vi chiederà se volete vedere tutte quante.
Tab Tab Mostra le possibilità di completamento di file o comandi.
Le ultime due voci nella soprastante tabella richiedono alcune spiegazioni extra. Per esempio, se volete spostarvi nella directory directory_dal_nome_piuttosto_lungo, non dovete
digitare assolutamente tutto quel lunghissimo nome. Dovete solo battere nella linea di comando cd dir e poi premere il tasto Tab: la shell provvedere a completare il nome per voi se non esistono altri
file che iniziano con gli stessi tre caratteri. Naturalmente se non esistono altre parole che iniziano
con “d”, allora potete digitare solamente cd d e poi Tab. Se più di un file inizia con gli stessi
caratteri, la shell ve lo segnalerà, dopo di che potrete battere due volte Tab di seguito e la shell
mostrerà le scelte disponibili.
Calcolo del determinate di una Matrice 4×4
Ecco il codice del sorgente C++:
#define CRT_SECURE_NO_WARNINGS
#include
float M[2][2],Ma[3][3],Matr[4][4];
float Determinante () {
float det;
det=M[0][0]*M[1][1]-M[0][1]*M[1][0];
return det;
}
float Det3X3 () {
float det=0,c;
int i,j,z=-1,n=3,x,y=0;
do
{
i=0;
j=1;
x=-1;
z=z+1;
if (z%2==0) c=Ma[z][0];
else c=Ma[z][0]*-1;
while (i<n)
{
if (i==z) i++;
if (i<n) {
j=1;
y=0;
x++;
while (j<n)
{
M[x][y]=Ma[i][j];
y++;
j++;
}
i++;
}
}
det=det+Determinante()*c;
}
while (z<n-1);
return det;
}
void main (void) {
int i,j,n,k,x,y;
float det,c;
do
{
printf ("Inserisci Ordine Matrice : ");
scanf ("%d",&n);
}
while (n4);
for (i=0;i<n;i++) for (j=0;j<n;j++) {
printf (" Inserisci numero [%d][%d]",i,j);
scanf ("%f",&Matr[i][j]);
};
if (n==1) det=Matr[0][0];
else {
if (n==2) { for (i=0;i<n;i++) for (j=0;j<n;j++) M[i][j]=Matr[i][j]; det=Determinante();}
else {
if (n==3) { for (i=0;i<n;i++) for (j=0;j<n;j++) Ma[i][j]=Matr[i][j];det=Det3X3();}
else {
k=-1;
det=0;
do {
k++;
i=0;
j=1;
x=-1;
if (k%2==0)c=Matr[k][0];
else c=Matr[k][0]*-1;
while (i<n)
{
if (i==k) i++;
if (i<n) {
j=1;
y=0;
x++;
while (j<n)
{
Ma[x][y]=Matr[i][j];
y++;
j++;
}
i++;
}
}
det=Det3X3()*c+det;
}
while (k<n-1);
}
}
}
printf ("Il determinante e' %f ",det);
getchar();
getchar();
};
Questo programma è in grado di calcolare il determinante di una matrice con indice massimo = 4
Puntatori
I puntatori sono dei tipi di variabili che contengono l’indirizzo di memoria di un’altra variabile.
Questo concetto è utile per creare una struttura dinamica di dati, cioè inserire direttamente nella memoria una quantità di dati indefinita senza avere dei limiti, che invece si avevano per un vettore. Ovviamente niente è infinito nell’informatica, però rispetto ai vettori si ha una minor limitazione nell’inserimento di dati. Per fare ciò bisogna creare una nuova struttura, solitamente chiamata nodo , che contenga una variabile dato di un qualsiasi tipo, e una variabile di tipo puntatore,solitamente succ, che punti ad un altra struttura di tipo nodo. Facendo ciò durante un allocazione dinamica si va a creare una struttura ricorsiva che contiene tutti i dati inseriti in input. Eccone un esempio:
Linguaggio C++
struct Nodo {
int Dato;
Nodo *succ;
}
I dati solitamente vengono gestiti in due modi: L’ultimo ad entrare è il primo ad essere prelevato (LIFO) ciò avviene anche nello stack della memoria del computer (PILA), oppure il primo ad entrare è il primo ad uscire (FIFO) tipico delle liste (CODA).
Sia la pila che la coda hanno uno specifico algoritmo che viene utilizzato anche per la gestione dinamica di dati.
La pila deve avere due variabili, per esempio, Testa e Fine, inizialmente inizializzate entrambe all’ultimo indirizzo di memoria disponibile. Mano a mano che si inseriscono dati il valore di Testa decrementa sempre di 1, mentre il valore Fine rimane fisso al valore inizializzato. Se si vuole prelevare un dato dalla pila il valore di Testa viene incrementato di 1 e il valore prelevato corriponde all’ultimo valore inserito in input.
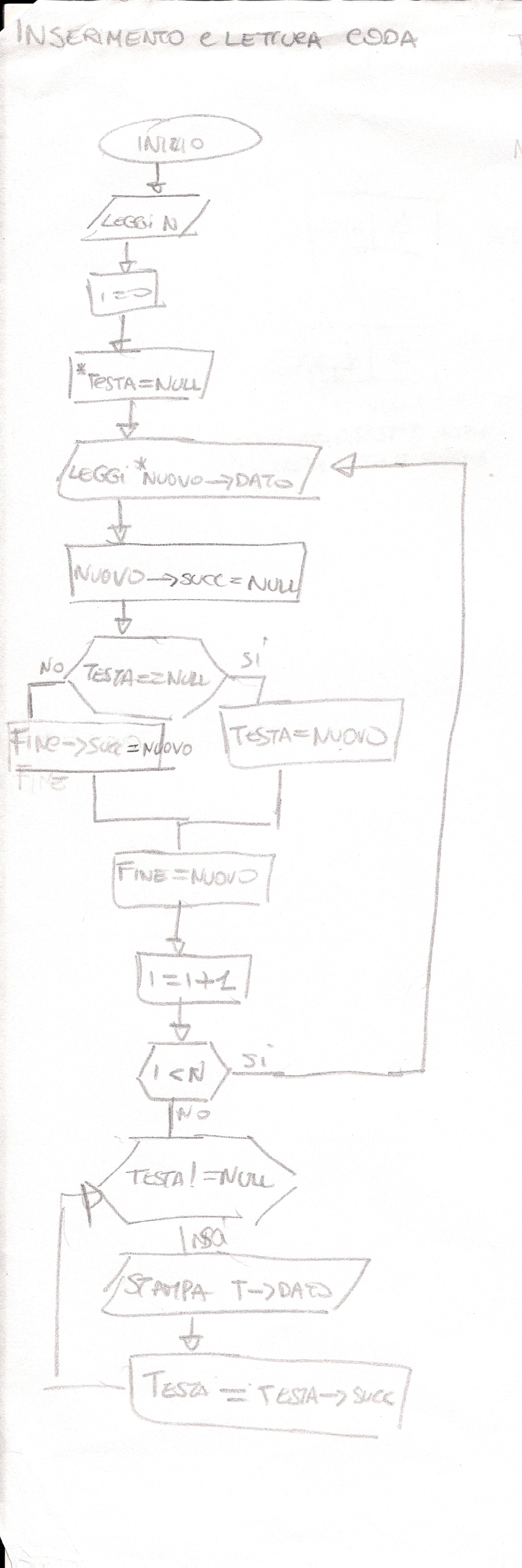
La coda funziona similmente alla pila. Utilizzando sempre le variabili Testa e Fine , vengono entrambe inizializzate al primo indirizzo di memoria disponibile e durante l’inserimento il valore di Testa rimane fisso mentre il valore di Fine incrementa di 1. Per prelevare un dato dalla coda bisogna eliminare il valore presente in Testa e shiftare tutti i valori verso Testa e decrementando la Fine di 1.
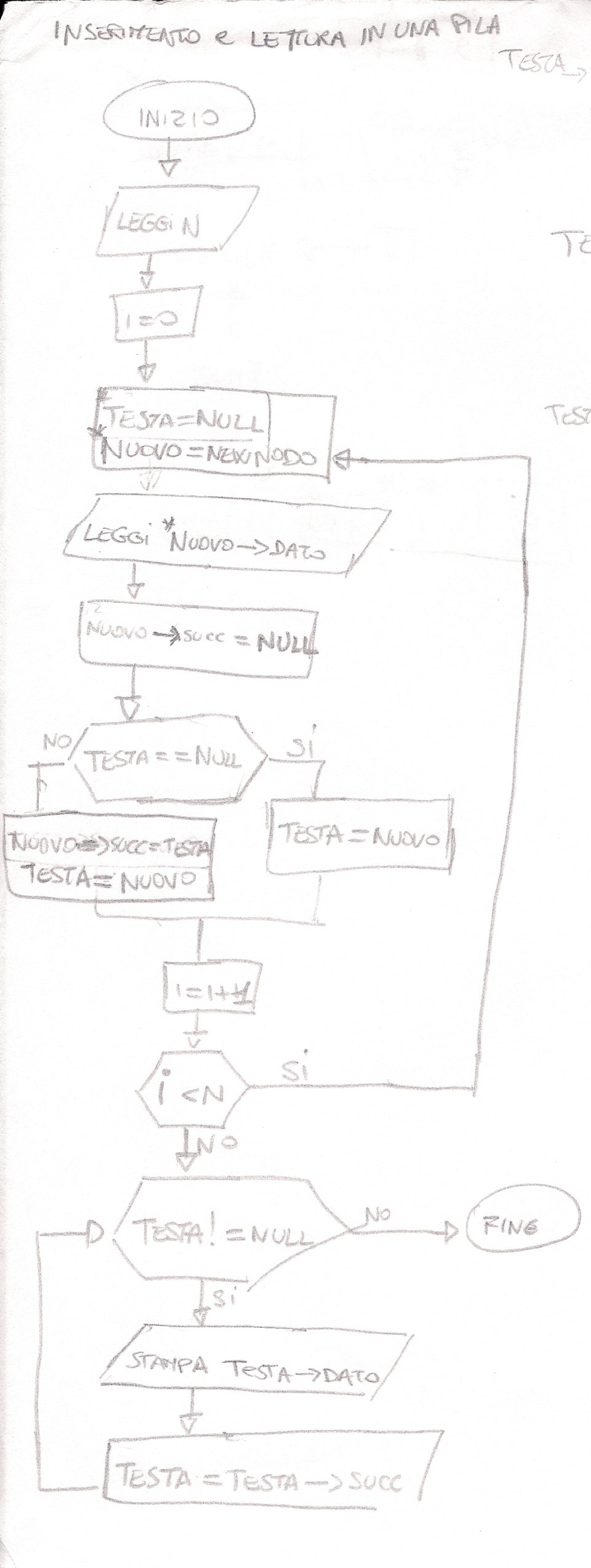 ———————————————————————————————————
———————————————————————————————————
Dopo Testa=Null occere mettere Nuovo=new Nodo;
Codice C++ Inserimento e lettura Pila:
#define CRT_SECURE_NO_WARNINGS 0
#include <stdio.h>
struct Nodo {
int Dato;
Nodo *succ;
};
void main (void) {
int n,i=0;
Nodo *Nuovo,*Testa=NULL, *p;
printf (“Inserisci n “);
scanf (“%d”,&n);
for(i=0;i<n;i++){
Nuovo=new Nodo;
printf (“\n Inserisci Dato : “);
scanf (“%d”,&Nuovo->Dato);
Nuovo->succ=Testa;
Testa=Nuovo;
}
p=Testa;
while (p!=NULL) {
printf (“\n Dato : %d”, p->Dato);
p=p->succ;
}
getchar();
getchar();
}
____________________________
Codice C++ Inserimento e lettura Coda :
#define _CRT_SECURE_NO_WARNINGS 0
#include <stdio.h>
struct Nodo {
int Dato;
Nodo *succ;
};
void main (void) {
int n,i=0;
Nodo *Nuovo,*Testa=NULL,*Fine,*p;
printf (“Inserisci n “);
scanf (“%d”,&n);
for(i=0;i<n;i++){
Nuovo=new Nodo;
printf (“\n Inserisci Dato : “);
scanf (“%d”,&Nuovo->Dato);
Nuovo->succ=NULL;
if (Testa==NULL){
Testa=Nuovo;
}
else Fine->succ=Nuovo;
Fine=Nuovo;
}
p=Testa;
while (p!=NULL) {
printf (“\n Dato : %d”, p->Dato);
p=p->succ;
}
getchar();
getchar();
}
Conversione di un numero inserito da tastiera
Esercitazione
Realizzare un programma assembler 80×86 in grado di convertire una sequenza di caratteri compresi fra ‘0‘ e ‘9‘ ,terminante con il valore ‘0dh‘ (invio), in numero decimale salvato nella variabile ‘tot’. L’operazione di conversione deve essere realizzata in una procedura.
Codice Assembler :
org 100h
mov cl,-1
salto:
mov ah,01h
int 21h ;Interruzione Input.
cmp al,0dh ; Verifica che il carattere sia diverso da (invio).
jz fine
sub al,’0′ ; Trasforma in decimale il valore ascii del numero.
mov bl,9
cmp bl,al ;Controlla che il carattere inserito sia un numero da ‘0’ a ‘9’.
jc fine
call conv ;Converte il numero in decimale.
jmp salto
fine:
ret
conv proc
mov bl,al
inc cl
ciclo:
cmp cl,0h
jz fine1
mov ax,10
mul tot
mov tot,ax
dec cl
fine1:
add tot,bx
ret
conv endp
tot dw 0
end

Procedure 1.1
Esercitazione
Realizzare un programma Assembler 80×86 in grado di leggere una sequenza di caratteri immessi dall’utente in input terminanti con il carattere “.“, in esadecimale “2eh“, in grado di contare quante ‘a‘ o ‘A‘ sono presenti nella stringa immessa. Tale risultato deve essere salvato nella variabile N . La stringa deve inoltre essere salvata in una variabile di tipo byte.
CONSIGLIO:
Poichè bisogna salvare ogni carattere in un unica variabile, quando si va a definirla bisogna utilizzare un particolare comando assembler (vedi guida) che crea una specie di “vettore“. Questo comando si chiama DUP e va utilizzato nella parte di codice tra il ret e l’end. Per esempio vett DB DUP (10) è il comando equivalente in C nello scrivere tipo VETT[10]; Ovvero nel creare un vettore (int,float,char …) di 10 elementi. Per dividere meglio il lavoro è bene crearesi 2 procedure (una per l’output a video e una per l’input da tastiera).
Algoritmo: 
org 100h ; add +100h to all addresses (required for .com file).
mov si,-1
ciclo:
inc si
call leggi
mov car[si],al
cmp al,’a’
jz incr
cmp al,’A’
jz incr
jmp avanti
incr:
inc n
avanti:
cmp al,’.’
jnz ciclo
mov al,0dh
call stampa
mov al,0ah
call stampa
mov al,n
add al,’0′
call stampa
ret
leggi proc
mov ah,01h
int 21h
ret
leggi endp
stampa proc
mov ah,0eh
int 10h
ret
stampa endp
n db 0
car db dup(20) ; Equivalente C di : Car[20]; .
end
Procedure (funzioni)
Una procedura è una parte di codice che può essere richiamata dal programma col fine di realizzare un operazione specifica. L’utilizzo di procedure rendono un programma più strutturato e più facile da capire. In Assembler 80×86 una procedura viene dichiarata fra l’istruzione RET e l’istruzione END insieme alla dichiarazione di altre variabili (DB, DW). La procedura è concettualmente identica ad una funzione in un linguaggio ad alto livello come il C++. Ad esempio se devo creare una procedura che mi sposti nel contenuto di bx il valore 0c3h devo rispettare una certa sintassi. Eccone un esempio:
ORG 100h
…
…
call FUNZIONE ; Con il comando call viene richiamata la procedura FUNZIONE dichiarata sotto il ret
ret
FUNZIONE proc ; In questa parte di programma viene dichiarata la procedura
mov bx, 0c3h
ret ; Con l’istruzione ret al termine dei comandi della procedura,essa viene terminata
FUNZIONE endp ; Con il comando endp il programma torna al punto in cui il programma ha richiamato la proc.
end
ESERCITAZIONE
Realizzare un programma assembler 80×86 che fornitogli in input dall’utente una sequenza di caratteri terminata dal tasto INVIO , ” corrispondente valore esadecimale 0dh“, stampi il carattere con il valore esadecimale maggiore. Il programma deve avere 2 procedure che richiamano 2 interruzioni , una per l’INPUT da tastiera e l’altra per l’OUTPUT sullo schermo.
Es. input: 123abcef7kz output : z
Ecco il codice Assembler:
org 100h ; add +100h to all addresses (required for .com file).
mov bl,0
ciclo:
call leggi
cmp al,0dh
jz fine
cmp bl,al
jnc ciclo
mov bl,al
jmp ciclo
fine:
call stampa
ret
stampa proc
mov ah,0eh
mov al,0ah
int 10h
mov al,0dh
int 10h
mov al,bl
int 10h
ret
stampa endp
leggi proc
mov ah,01h
int 21h
ret leggi endp
end
Linguaggio Assembler 80×86
Un assemblatore è un software che trasforma le istruzioni mnemoriche in linguaggio macchina. Si tratta dunque di un compilatore per un particolare linguaggio assembly. Ci sono molti tipi di linguaggi assembly e di conseguenza diversi assemblatori: esistono gli assembler per programmare i microchip, per creare programmi sul Personal Computer per telefoni cellulari, ecc. Questo perché un assemblatore produce linguaggi macchina per una specifica famiglia di processori (intel 8086, 80386,Motorola 68000, ecc.). Per saper usare bene questo tipo di linguaggio a basso livello occorre avere delle conoscenze sulla struttura hardware del computer. Ad esempio dentro la CPU ci sono vari registri alcuni riservati a particolari funzioni altri per contenere risultati. Sotto è riportato un breve schema della struttura dei registri e dei flag (particolari segnalatori presenti nell’alu, utili all’utente per far eseguire alcune istruzioni quando si verificano particolari condizioni). La maggior parte dei registri sono a 16 bit tranne i sottoregistri (AH,AL,BH,BL.CH.CL.DH,DL) che sono a 8 bit. Uno dei registri più importanti è IP,il quale contiene il valore dell’indirizzo della prossima istruzione che il programma deve eseguire. I registri (CS,DS,ES,SS) sono registri di tipo segmento che indicano su che zona di memoria il programma sta lavorando.Per accedere a particolari zone di memoria (stack) bisogna far riferimento a particolari registri e bisogna utiliazzarli nel seguente modo:
La maggior parte dei registri sono a 16 bit tranne i sottoregistri (AH,AL,BH,BL.CH.CL.DH,DL) che sono a 8 bit. Uno dei registri più importanti è IP,il quale contiene il valore dell’indirizzo della prossima istruzione che il programma deve eseguire. I registri (CS,DS,ES,SS) sono registri di tipo segmento che indicano su che zona di memoria il programma sta lavorando.Per accedere a particolari zone di memoria (stack) bisogna far riferimento a particolari registri e bisogna utiliazzarli nel seguente modo: Un semplice esempio è spostarsi alla zona di memoria di offset 150 e portare in memoria il valore esadecimale “4eh”. Il codice assembler sarà strutturato nel seguente modo :
Un semplice esempio è spostarsi alla zona di memoria di offset 150 e portare in memoria il valore esadecimale “4eh”. Il codice assembler sarà strutturato nel seguente modo :
ORG 100h
mov bx,150h ; In questo modo si sposta l’indice all’offset 150h
mov [bx],4eh ; indicando il registro interessato tra [ ] si sposta in memoria il valore 4eh
ret
end
Il comando MOV funziona come operatore di assegnazione e nella sintassi viene prima specificata la destinazione seguita da una “,” e dalla sorgente. L’Assembler 80×86 possiede una gamma di istruzioni impostate che permettono di eseguire particolari operazioni. Per saperne di più consulta una guida.
 L’Assembler 80×86 mette a disposizione la possibiltà di eseguire delle interruzioni di tipo software ovvero particolari operazioni che richiamo dei concetti salvati in una zona di memoria interrompendo temporaneamente l’esecuzione del programma, come ad esempio stampare sullo schermo ciò che si è elaborato oppure leggere da tastiera un dato immesso dall’utente. Utilizzando il registro AH e l’istruzione INT in modo opportuno è possibile effettuare un interruzione di tipo Software.
L’Assembler 80×86 mette a disposizione la possibiltà di eseguire delle interruzioni di tipo software ovvero particolari operazioni che richiamo dei concetti salvati in una zona di memoria interrompendo temporaneamente l’esecuzione del programma, come ad esempio stampare sullo schermo ciò che si è elaborato oppure leggere da tastiera un dato immesso dall’utente. Utilizzando il registro AH e l’istruzione INT in modo opportuno è possibile effettuare un interruzione di tipo Software.
Mediante l’utilizzo di un Debug il programmatore può vedere come vengono modificati i registri e i flag istruzione per istruzione correggendo quindi eventuali errori logici.
Moda,Media,Mediana: Algoritmo e Codice C
Il programma deve essere in grado di calcolare, data in input dall’utente una sequenza di numeri x [ i ] con le relative frequenze f [ i ], il valore della MODA, MEDIA e MEDIANA. Inoltre se sono presenti più valori con la stessa frequenza deve comunicare all’utente che non è possibile calcolare la moda. Se un numero x [ i ] si presenta più di una volta, deve essere reinserito correttamente dall’utente.
Ecco il diagramma a blocchi (algoritmo) del programma :
")
")
")
Programma in C :
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
void main (void) {
int i,k,j,somma_freq,f[10],n,app=0,max;
float x[10],somma,mediana,v[1000],min;
do
{
printf (” Quanti numeri vuoi inserire? : “);
scanf (“%d”,&n);
}
while (n<0 || n>10);
do {
somma_freq=0;
somma=0;
for (i=0;i<n;i++) {
do {
printf (“\nInserisci il numero x[%d] : “,i);
scanf (“%f”,&x[i]);
j=0;
for(k=0;k<i;k++) {
if (x[i]==x[k]){
k=i+1;
j=1;
printf (“\nHai gia’ immesso questo numero\n”);
}
}
}
while (j==1);
printf (“\nInserisci la frequenza f[%d] : “,i);
scanf (“%d”,&f[i]);
somma=x[i]*f[i]+somma;
somma_freq=somma_freq+f[i];
}
if (somma_freq>1000) printf (“\n La somma delle frequenze e’ maggiore di 1000 “);
}
while (somma_freq>1000);
for (k=0;k<n;k++) {
min=x[k];
for (i=k+1;i<n;i++) if (x[i]<min) {
min=x[i];
x[i]=x[k];
x[k]=min;
j=f[i];
f[i]=f[k];
f[k]=j;
}
};
system (“cls”);
printf(” X(i) | F (i) \n\n”);
for (i=0;i<n;i++) printf (” %.2f %d \n\n”);
j=f[0];
max=0;
for (i=1;i<n;i++) if (f[i]>j) {
j=f[i];
max=i;
app=0;
}
else if (f[i]==j) app++;
j=0;
for (k=0;k<n;k++) {
for (i=0;i<f[k];i++,j++) v[j]=x[k];
}
if (somma_freq%2==0) mediana= (v[somma_freq/2]+v[somma_freq/2-1])/2;
else mediana=v[somma_freq/2];
if (app>0) printf (“\n Non e’ possibile determinare la moda; %d frequenze sono dello stesso valore”,app+1);
else printf (“\n La Moda e’ : %.2f “,x[max]);
printf (“\n La Media e’ : %.2f “,somma/somma_freq);
printf (“\n La Mediana e’ : %.2f “,mediana);
getchar();
getchar();
}
Calcolo delle probabilità
Il concetto di probabilità è stato introdotto nel ‘600, ed esso viene impiegato oggi anche nel linguaggio di tutti i giorni, per indicare una situazione di incertezza o a fenomeni che possono o meno accadere:

A questo concetto sono legati eventi incerti, come la probabilità che da un cesto in cui troviamo palline bianche, blu e azzurre, venga estratta una pallina bianca. Questo evento viene definito aleatorio. Opposto a tale concetto troviamo gli eventi impossibili, come la possibilità che da un cesto in cui ci sono palline bianche, blu e azzurre, venga estratta una pallina rossa.
Esistono vari tipi di probabilità :
- Probabilità Matematica P(E)definita dal rapporto tra il numero (m) dei casi favorevoli e il numero (n) dei casi possibili.
La formula risultante è quindi: P(E)=m/n. - Probabilità Statistica o a Posteriori P(S) definita dal rapporto dei casi verificati (cv) e il numero dei casi possibili (cp). In formula : P(S)= cv/cp.
- Probabilità Soggettiva non esiste formula matematica che la descriva, è data dalla probabilità matematica dell’evento integrata con valutazioni soggettive riferite ai singoli casi.
Il mio primo articolo!
Questa è SpartaaaaaaaaaaaaaaaaAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA!
